
Orchest is an open source tool for building data science pipelines. It integrates with the existing PyData / R workflow that many data scientists already have. Below is our recent interview with Rick Lamers, CEO & Co-Founder at Orchest:

Q: Who is your ideal user and why?
A: Our ideal user is someone who is more interested in spending time with their data and models than with cloud infrastructure and plumbing. We let the data scientist focus on their core activities instead of getting distracted by managing Virtual Machines, setting up development environments and integrating and connecting various open source tools and libraries to work well together.
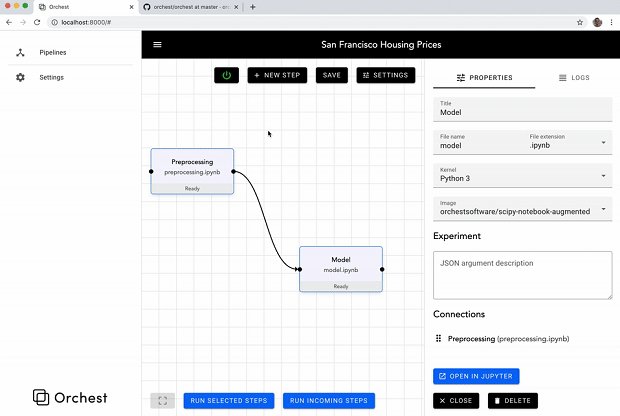
Q: What are your core features?
A: We provide a simple & clean GUI for constructing and managing the data pipelines, however we are fully focused on a ‘high code’ approach when it comes to the actual pipeline steps. In addition we provide:
– A scheduler that can run multiple pipelines and their steps in parallel by using containers under the hood.
– Simple key/value parameterization of pipelines for rapid experimentation and reuse.
– An easy way to customize your container environments with bash scripts directly in your browser (`pip install tensorflow~=1.15.0` anybody?).
– Data source abstractions to make it simple to develop data pipelines without hardcoded data sources (e.g. simply swap from staging to production databases without touching your pipeline code).
Q: What makes your company the best choice for creating data science pipelines?
A: Orchest is super easy to use, but can support complicated and state of the data science techniques such as distributed GPU based deep learning. We provide sane defaults so you don’t have to think about most things, unless you really want to. It Just Works™.
![]() Recommended: Biofourmis Combines The Power Of AI With Data To Enable Personalized Healthcare
Recommended: Biofourmis Combines The Power Of AI With Data To Enable Personalized Healthcare
Q: What can we expect from Orchest in next 6 months?
A: That product & community is developing rapidly. Expect constant improvements and a growing number of Orchest pipelines in the wild that can be imported into Orchest as starter templates to kickstart your ideas with.
